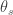Lateral Gene Transfer from the Dead
Szöll\Hosi GJ, Eric Tannier, Nicolas Lartillot, Vincent Daubin
(Submitted on 19 Nov 2012)
In phylogenetic studies, the evolution of molecular sequences is assumed to have taken place along the phylogeny traced by the ancestors of extant species. In the presence of lateral gene transfer (LGT), however, this may not be the case, because the species lineage from which a gene was transferred may have gone extinct or not have been sampled. Because it is not feasible to specify or reconstruct the complete phylogeny of all species, we must describe the evolution of genes outside the represented phylogeny by modelling the speciation dynamics that gave rise to the complete phylogeny. We demonstrate that if the number of sampled species is small compared to the total number of existing species, the overwhelming majority of gene transfers involve speciation to, and evolution along extinct or unsampled lineages. We show that the evolution of genes along extinct or unsampled lineages can to good approximation be treated as those of independently evolving lineages described by a few global parameters. Using this result, we derive an algorithm to calculate the probability of a gene tree and recover the maximum likelihood reconciliation given the phylogeny of the sampled species. Examining 473 near universal gene families from 36 cyanobacteria, we find that nearly a third of transfer events — 28% — appear to have topological signatures of evolution along extinct species, but only approximately 6% of transfers trace their ancestry to before the common ancestor of the sampled cyanobacteria.